Proposal For A More Scalable Linux Scheduler
aka
Balanced Multi Queue Scheduler
by
Davide Libenzi
<davidel@xmailserver.org>
Sat 12/01/2001
Episode [2]
Captain's diary, tentative 2, day 2 ...
This is the second version of the Balanced Multi Queue Scheduler ( BMQS ) for the Linux kernel that maintain the basic concept of the previous version plus adding a new balancing method against the very simple one coded in the first implementation. The basic idea that drives this implementation is to increase the scheduler locality by adding multiple queues ( one for each CPU ) and multiple locks ( one for each CPU ) to achieve the lower interlocking between independent CPUs when running the scheduler code. The first implementation is described here so I'll skip listing all the issues that are solved/improved by using a multi queue scheduler with independent locks. This new version contain a way better/faster balancing code plus other features/improvements to the current scheduler code. A first change to the old implementation is the adoption inside local CPU schedulers of the "Time Slice Split Scheduler" that Linus merged in 2.5.2-pre3 and this achieve multiple objectives like priority inversion proof for CPU bound tasks, way shorter worst case scheduler latency due running-only recalculation loop, a better accumulated virtual time distribution and a better sys_sched_yield() implementation. A brief desription of these achievements is contained here. The next change to the previous implementation is the introduction of global real time tasks. With this implementation two kind of RT tasks are allowed, local RT tasks that lives inside their local CPU run queue and that do not have global preemption capability, and global RT tasks that lives in the special run queue RT_QID and that have global preemption capability. For global preemption capability is meant the ability that global RT tasks have to preempt tasks running on remote CPUs in case their better/last CPU is currently running another RT tasks when they're woke up. A new flag SCHED_RTLOCAL has been introduced to give to the function setscheduler() the ability to create local RT tasks, which if not specified default to global RT task. RT tasks may run on every CPU and their presence is fast checked without held locks before the standard run queue selection :
[kernel/sched.c]
if (grt_chkp != rtt_chkp(cpu_number_map(this_cpu))
&&
!list_empty(&runqueue_head(RT_QID)))
goto rt_queue_select;
A variable :
[kernel/sched.c]
static volatile unsigned long grt_chkp = 0;
is declared and is incremented at every global real time task wakeup ( see below, rtt_reschedule_idle() ) and a per-CPU variable rtt_chkp is used to keep track of global real time tasks checkpoint. When the pickup inside the global real time queue fail ( all global real time tasks have a CPU ) the per-CPU variable rtt_chkp is aligned to the global variable grt_chkp avoiding scheduler latency degradation for normal tasks when global real time tasks are running. The function reschedule_idle() is now split ( in the SMP case ) to perform different tasks required by global RT tasks wake up :
[kernel/sched.c]
static void reschedule_idle(struct task_struct * p)
{
#ifdef CONFIG_SMP
if (!global_rttask(p))
std_reschedule_idle(p);
else
rtt_reschedule_idle(p);
#else /* #ifdef CONFIG_SMP */
struct task_struct *tsk;
tsk = cpu_curr(smp_processor_id());
if (preemption_goodness(tsk,
p) > 0)
tsk->need_resched = 1;
#endif /* #ifdef CONFIG_SMP */
}
The function std_reschedule_idle() is used to preempt ( eventually ) tasks on the local CPU, is used for standard tasks ( and local RT tasks ) and is a stripped down version of the one coded inside the old scheduler. This version is way faster compared to the original version because in a multi queue scheduler tasks are local by default and no idle discovery loop is performed inside std_reschedule_idle() :
[kernel/sched.c]
static inline void std_reschedule_idle(struct task_struct * p)
{
int best_cpu = p->task_qid,
this_cpu = cpu_number_map(smp_processor_id());
struct task_struct *tsk;
tsk = cpu_curr(best_cpu);
if (tsk == idle_task(cpu_logical_map(best_cpu)))
{
int need_resched = tsk->need_resched;
tsk->need_resched = 1;
if ((best_cpu != this_cpu) && !need_resched)
smp_send_reschedule(cpu_logical_map(best_cpu));
} else if (tsk != p
&& preemption_goodness(tsk, p) > 0) {
tsk->need_resched = 1;
if (tsk->task_qid != this_cpu)
smp_send_reschedule(cpu_logical_map(tsk->task_qid));
}
}
A test to find out if the CPU of the woke up tasks is idle is first performed, and if this is the case the CPU is rescheduled ( by an IPI if it's not the current CPU ) to allow it to pickup the new run queue task. Otherwise a preemption_goodness() between the task currently running on the best CPU of the woke up task and the woke up task is perfomed to find out if the woke up task has the right to preempt the currently running one. If no one of this cases are matched, the woke up task is simply left inside its own local CPU and it's responsibility of the balancing code to get global moving decisions and eventually reschedule the task on different/unloaded CPUs. As I said before, global RT tasks have global preemption capability and their wakeup must be handled in a different way. This is currently achieved inside the function rtt_reschedule_idle() :
[kernel/sched.c]
static inline void rtt_reschedule_idle(struct task_struct * p)
{
int cpu, best_cpu =
cpu_number_map(p->processor),
this_cpu = cpu_number_map(smp_processor_id()), need_resched, maxpg = 0,
pg;
struct task_struct *tsk,
*ttsk = NULL;
if (can_schedule(p, cpu_logical_map(best_cpu)))
{
spin_lock(&runqueue_lock(best_cpu));
tsk = cpu_curr(best_cpu);
if (!task_realtime(tsk)) {
need_resched = tsk->need_resched;
tsk->need_resched = 1;
if (best_cpu != this_cpu &&
(!need_resched || tsk != idle_task(cpu_logical_map(best_cpu))))
smp_send_reschedule(cpu_logical_map(best_cpu));
spin_unlock(&runqueue_lock(best_cpu));
return;
}
spin_unlock(&runqueue_lock(best_cpu));
}
for (cpu = 0; cpu <
smp_num_cpus; cpu++) {
if (can_schedule(p, cpu_logical_map(cpu))) {
spin_lock(&runqueue_lock(cpu));
tsk = cpu_curr(cpu);
if (!task_realtime(tsk)) {
need_resched = tsk->need_resched;
tsk->need_resched = 1;
if (cpu != this_cpu &&
(!need_resched || tsk != idle_task(cpu_logical_map(cpu))))
smp_send_reschedule(cpu_logical_map(cpu));
spin_unlock(&runqueue_lock(cpu));
return;
}
spin_unlock(&runqueue_lock(cpu));
}
}
lock_queues();
for (cpu = 0; cpu <
smp_num_cpus; cpu++) {
if (can_schedule(p, cpu_logical_map(cpu))) {
tsk = cpu_curr(cpu);
if ((pg = preemption_goodness(tsk, p)) > maxpg) {
ttsk = tsk;
maxpg = pg;
if (tsk == idle_task(cpu_logical_map(cpu)))
break;
}
}
}
if (ttsk) {
need_resched = ttsk->need_resched;
ttsk->need_resched = 1;
if (ttsk->processor != smp_processor_id() && !need_resched)
smp_send_reschedule(ttsk->processor);
}
unlock_queues();
}
This function first tries to see if the CPU where the global RT
task is ran the last time is not running another RT task, and if this is
the case that CPU is rescheduled either locally ( need_resched ) or remotely
( need_resched + IPI ). The next loop is to try to find a CPU that is not
running another RT task ( either local or global ) avoiding to get the
whole lock set and counting on the probability's theory that will grant
us a fewer locks traffic over the solution of immediately get the whole
lock set. If all the system's CPUs are currently running RT tasks the function
rtt_reschedule_idle() must lock the whole set and perform a
preemption_goodness() loop to find the CPU that is running the less
priority RT task and enforcing a rechedule on that CPU. Ending the discussion
about the new implementation of RT tasks it must be noted that, by having
a separate run queue, the scheduler latency of these global RT tasks is
lower compared to the one available with the current scheduler. Another
slight change respect to the previous version is
the removal of the balancing hook from the architecture dependent
cpu_idle() ( arch/??/kernel/process.c ) to the architecture independent
schedule() ( in kernel/sched.c ). Another improvement of having per
CPU tasks list is the shorter recalculation loop that, in system with lot
of processes, can make the worst case scheduler latency very bad. For example
in my system where a typical context switch takes from 1000 up to 2500
cycles, having something like 100 processes listed by `ps`, could make
the recalculation loop to take about 40000 cycles ( and 100 processes listed
by `ps` are not a huge number ).
If having an independent, multi queue scheduler with fine grained
locks is good for a number of reasons, it's even true that without a good
balancing scheme the system could experience bad load distribution by leaving
a large amount of CPU cycles free on certain CPUs with tasks on other CPUs
waiting for CPU cycles. It must be noted that coding an efficent balancing
scheme is not trivial because it should be adaptable to different systems
with different topology maps and different costs related to inter-CPU process
moves. This is true for NUMA systems, where the cost of moving tasks inside
a node is typically different from the cost of moving tasks between different
nodes, and it's true for multi core CPUs ( more CPU inside a single die
), where the cost of intra-die move is lower compared with an extra-die
move ( and eventually an extra node move ). The balancing code is triggered
when a schedule() result in an idle task pickup, and its code
resides inside kernel/sched.c. The difference from the previous implementation
of this multi queue scheduler is that the idle task ( when running ) is
wake up at every timer tick :
[kernel/timer.c]
void update_process_times(int user_tick)
{
struct task_struct *p
= current;
int cpu = smp_processor_id(),
system = user_tick ^ 1;
update_one_process(p,
user_tick, system, cpu);
if (p->pid) {
expire_task(p);
if (p->nice > 0)
kstat.per_cpu_nice[cpu] += user_tick;
else
kstat.per_cpu_user[cpu] += user_tick;
kstat.per_cpu_system[cpu] += system;
} else {
sched_wake_idle();
if (local_bh_count(cpu) || local_irq_count(cpu) > 1)
kstat.per_cpu_system[cpu] += system;
}
}
When the current task is the idle one ( pid == 0 ) the function sched_wake_idle() is called :
[kernel/sched.c]
void sched_wake_idle(void)
{
if (smp_num_cpus > 1)
current->need_resched = 1;
}
With this implementation the idle is rescheduled at every timer tick but a code that takes in account the HZ value can easily be implemented to avoid calling the balancing code too often ( for example in architectures with HZ > 1000 ). The first concept upon which is based the balancing code is a "CPU Distance Map" or "CPU Topology Map" that is nothing more than an 2D array storing CPU "distances" :
[kernel/sched.c]
unsigned char cpus_dmap[NR_CPUS][NR_CPUS];
#define cpu_distance(i, j) (cpus_dmap[i][j])
Where the distance between CPUs I and J will be defined to be cpus_dmap[I][J]. This matrix is symmetric ( cpus_dmap[i][j] == cpus_dmap[j][i] ) and the definition of distance between CPU I and CPU J can be thought as the number of timer ticks an idle task, running on the CPU I and observing an overload on the CPU J ( or viceversa ), is allowed to run before triggering task stealing from the loaded CPU. By fixing the maximum allowed idle time in milliseconds ( MSI ) the CPU distance value will be :
cpus_dmap[i][j] = ( MSI(i, j) * HZ ) / 1000
By fixing the CPU distance to zero the scheduler will behave much like the current one with tasks that are moved to the idle CPU as soon as possible. Being expressed in the above way the distance will have HZ granularity, but this is not a problem because 1) a 10 ms resolution has been found sufficent 2) the HZ value can be easily increased with today's CPU speed. When the idle task is selected inside the schedule() function the balancing code is triggered :
[kernel/sched.c]
#ifdef CONFIG_SMP
if (unlikely(current
== idle_task(this_cpu)))
if (get_remote_task(this_cpu))
goto need_resched_back;
#endif /* #ifdef CONFIG_SMP */
The code that perform balance checking is quite simple :
[kernel/sched.c]
static long move_cost(int src_cpu, int dst_cpu)
{
return (cpu_distance(src_cpu,
dst_cpu) << 4) -
(qnr_running(src_cpu) * mvtsk_cost * (HZ << 4)) / 1000;
}
static inline struct task_struct *get_remote_task(int this_cpu)
{
int i, max_cpu;
unsigned long hcpus
= 0;
long ccost, min_cost;
struct task_struct *rtask;
this_cpu = cpu_number_map(this_cpu);
for (i = 0; i < smp_num_cpus;
i++) {
if (i == this_cpu) continue;
if (qnr_running(i) >= min_mov_rqlen) {
if (hit_cpus(this_cpu) & (1 << i))
++ldhits(this_cpu, i);
else {
hit_cpus(this_cpu) |= (1 << i);
ldhits(this_cpu, i) = 1;
}
if (ldhits(this_cpu, i) >= cpu_distance(this_cpu, i))
hcpus |= (1 << i);
} else
hit_cpus(this_cpu) &= ~(1 << i);
}
while (hcpus) {
max_cpu = -1;
min_cost = 1000;
for (i = 0; i < smp_num_cpus; i++) {
if (!(hcpus & (1 << i))) continue;
if ((ccost = move_cost(i, this_cpu)) < min_cost) {
min_cost = ccost;
max_cpu = i;
}
}
if (max_cpu < 0) break;
if ((rtask = try_steal_task(max_cpu, this_cpu))) {
hit_cpus(this_cpu) = 0;
return rtask;
}
hcpus &= ~(1 << max_cpu);
}
return NULL;
}
This code loops between CPUs and try to find the CPU that 1) is overloaded ( compared to the variable min_mov_rqlen ) 2) has the lower move cost towards the remote loaded CPU. The move cost is defined :
MC(i, j) = DIST(i, j) * Kd - QNR(i) * Kq
where MC(i, j) is the move cost for moving a task from a loaded CPU i to an idle CPU j, DIST(i, j) is the CPU distance defined above, Kd is a scaling factor, QNR(i) is the run queue length on the CPU i and Kq is defined as :
Kq = Kd * ( MSTW * HZ ) / 1000
The variable MSTW is the weight of a run queue process expressed in milliseconds and is stored inside the variable :
[kernel/sched.c]
int mvtsk_cost = DEF_CPU_DIST_MS / 2 - 1;
In the code listed above the variable Kd is set to 16 ( << 4 ). The MC(i, j) formula can be thought in this way : We want to consider the distance between CPUs but if the difference in run queue load goes above a certain limit We better start unloading the farthest CPU instead of the nearest one. By lowering the value of mvtsk_cost We'll increase the isolation level of CPU nodes while increasing it will result in a lower isolation level. The code listed above is quite simple and try to find the loaded CPU that has the lesser move cost. If the same loaded CPU is found for more than DIST(i, j) times ( timer ticks ) the function try_steal_task() is called and it'll try to steal a task from the loaded remote CPU :
[kernel/sched.c]
static inline long move_goodness(struct task_struct *p, struct
mm_struct *this_mm)
{
long mgds = (long) (jiffies
- p->run_jtime);
if (p->mm == this_mm
|| !p->mm)
mgds += MOVE_MM_BONUS;
return mgds;
}
static inline struct task_struct *try_steal_task(int src_cpu, int
dst_cpu)
{
int ldst_cpu = cpu_logical_map(dst_cpu);
long mgdns = -1, mvg;
struct mm_struct *this_mm
= current->active_mm;
struct task_struct *tsk,
*mvtsk = NULL;
struct list_head *head,
*tmp;
spin_lock_irq(&runqueue_lock(src_cpu));
head = &runqueue_head(src_cpu);
list_for_each(tmp, head)
{
tsk = list_entry(tmp, struct task_struct, run_list);
if (can_move(tsk, ldst_cpu) && !task_foreign(tsk) &&
(mvg = move_goodness(tsk, this_mm)) > mgdns) {
mvtsk = tsk;
mgdns = mvg;
}
}
if (mvtsk) {
unsigned long cpus_allowed = mvtsk->cpus_allowed;
mvtsk->cpus_allowed = 0;
__del_from_runqueue(mvtsk, src_cpu);
spin_unlock(&runqueue_lock(src_cpu));
write_lock(&tasklist_lock);
spin_lock(&runqueue_lock(src_cpu));
__del_from_proclist(mvtsk, src_cpu);
spin_unlock(&runqueue_lock(src_cpu));
spin_lock(&runqueue_lock(dst_cpu));
mvtsk->rcl_last = rcl_curr(dst_cpu);
__add_to_runqueue(mvtsk, dst_cpu);
__add_to_proclist(mvtsk, dst_cpu);
mvtsk->cpus_allowed = cpus_allowed;
mvtsk->task_qid = dst_cpu;
spin_unlock(&runqueue_lock(dst_cpu));
write_unlock_irq(&tasklist_lock);
} else
spin_unlock_irq(&runqueue_lock(src_cpu));
return mvtsk;
}
This function will loop through the source CPU run queue finding the one with the higher move_goodness() and it'll remove the selected task ( if any ) from the loaded CPU by pushing it inside the idle queue. The move_goodness() function will select that task that has the older scheduler time ( jiffies - p->run_jtime ) by giving a slight advantage to tasks that have affine MM with the last task that was run on the currently idle CPU. Such MM affinity bonus is declared as :
[kernel/sched.c]
#define MOVE_MM_BONUS_MS 20
#define MOVE_MM_BONUS ((MOVE_MM_BONUS_MS
* HZ) / 1000)
and it's expressed in jiffies ( timer ticks ). By having a tunable sampling in the time domain the scheduler will behave like a tunable low-pass filter that will make it capable of avoid triggering tasks moves when high frequency load peaks are observed. So the mean of the distance map is both a value of the distance between CPUs and the cut-frequency that the low-pass filter will have when observing loads on remote CPUs. Finding the CPU for a new task is done inside task_cpu_place() that gets called from do_fork() inside kernel/fork.c :
[kernel/sched.c]
static long rt_cpu_dist(int src_cpu, int dst_cpu)
{
return (cpu_distance(src_cpu,
dst_cpu) << 4) +
(qnr_running(src_cpu) * mvtsk_cost * (HZ << 4)) / 1000;
}
int task_cpu_place(struct task_struct *p);
{
int i, best_cpu, this_cpu
= cpu_number_map(smp_processor_id());
long cdist, min_cdist;
best_cpu = this_cpu;
min_cdist = rt_cpu_dist(this_cpu,
this_cpu);
for (i = 0; i < smp_num_cpus;
i++) {
if (i == this_cpu || !run_allowed(p, cpu_logical_map(i))) continue;
if ((cdist = rt_cpu_dist(i, this_cpu)) < min_cdist) {
min_cdist = cdist;
best_cpu = i;
}
}
p->rcl_last = rcl_curr(best_cpu);
p->processor = cpu_logical_map(best_cpu);
p->task_qid = best_cpu;
return p->processor;
}
The function rt_cpu_dist() is symmetrical to move_cost()
and add the remote run queue weight to the inter CPU distance.
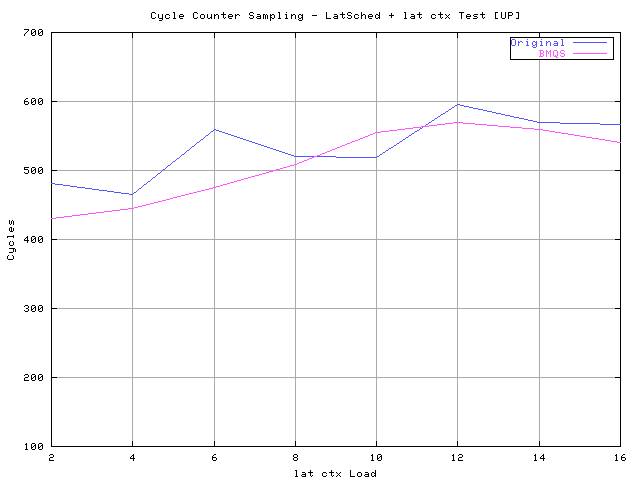
The first test is to check the scheduler latency on UP systems and my machine it's used for the test. It's an AMD 1GHz with 256Mb of RAM and the test kernel is 2.5.1-pre11. The machine is loaded with the lat_ctx program that creates a set of processes bouncing data between them, and the LatSched cycle counter latency patch ( Links[3] ) is used to sample the scheduler latency during the load. The schedcnt program ( Links[3] ) is used to collect latency samples :
# schedcnt --ttime 4 -- lat_ctx N N N N
with N that is the lat_ctx load that is shown in the X axis. The collection of 4000 samples is enough to stabilize the measure.
This shows a quite similar behavior/latency between the original ( 2.5.1-pre11 ) scheduler and the proposed implementation for uniprocessor systems. Actually the Balanced Multi Queue Scheduler behave quite a bit better but this could be caused by a better cache line alignment of the proposed implementation. What is important to show with this test is that the overall scheduler latency for uniprocessor systems is not affected by the new implementation. In this test the lat_ctx program is used to load the scheduler because, due the sys_sched_yield() optimization, benchmark suites that uses that function as context switch load will result in lower performance due the increased number of recalculation loops that this scheduler will perform in case of multiple yield()ers. In fact the proposed scheduler behave exactly like described at the beginning of this document, that means that it gradually drops the yield()er dynamic priority allowing not yield()ing tasks to be scheduled without wasting CPU cycles. The ones that want to use sys_sched_yield() based tests should use the same sys_sched_yield()'s code that is inside the original scheduler to avoid comparing oranges with apples. The next test uses the old sys_sched_yield() implementation inside the BMQS scheduler and the machine tested is a 2 way SMP dual PIII 733 MHz 256Mb RAM. The load is done through the lat-sched program ( Links[3] ) and the samples are collected with the cycle counter latency patch. The command line used is :
# schedcnt --ttime 6 -- lat-sched --ttime 16 --ntasks N
with N that is the real run queue length that will be
shown in the X axis. The initial run queue length is fixed to 4 because
the optimization inside the sys_sched_yield() function prevent
the context switch if the current number of tasks inside the run queue
is lower than two.
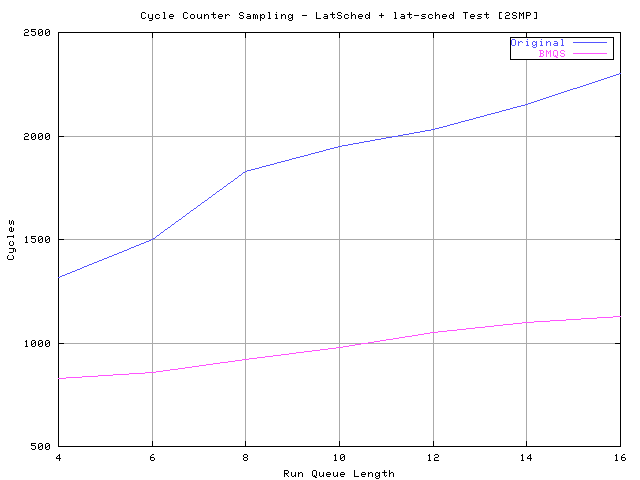
This test shows an improved latency starting from very low run queue loads and increasing when moving along positive X axis values. The causes of these results are both the split run queue and the removal of the common lock that, with high frequency lock operations, creates undesired cache coherency traffic effects. The next test, thanks to OSDLAB ( Links[6] ), uses an 8 way SMP with Intel PIII 700 MHz, 1Mb L2 and 16Gb of RAM. The test is run like the previous one :
# schedcnt --ttime 6 -- lat-sched --ttime 16 --ntasks N
The test starts with a run queue length ( N ) of 16 ( rqCPU == 2
) and ends up to a run queue length of 128 ( rqCPU == 16 ).
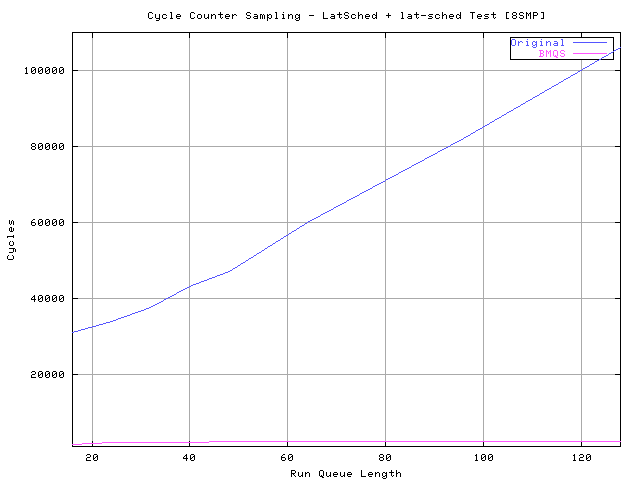
Like expected incresing the number of CPUs the performance gain
the the Balanced Multi Queue Scheduler achieve peaks up and is dramatic
starting from a run queue length of 16 ( BMQS cycles == 1417 , STD cycles
== 31081 ).
A succesive improvement to the proposed Balanced Multi Queue Scheduler
could be the split of the run queue list in two separate list, one that
holds CPU bound tasks and the other that store I/O bound tasks and RT tasks.
The io-rt-queue will be scanned like usual searching for the best task
to run inside such process set and, if one is found, it'll be scheduled
without checking the CPU bound tasks queue. The CPU bound tasks queue could
be either scanned as a FIFO ( getting an O(1) behavior ) or scanned normally
searching for the best pick. Scanning the CPU bound tasks queue in a FIFO
way will not break any fairness inside the time slice distribution because
CPU bound tasks ( batches ) does not need a strict execution order as long
as the total virtual time assigned to them is fair. When scanning the CPU
bound queue "normally" a priority inversion protection like the one coded
in this scheduler should be adopted. The advantage of implementing this
dual queue design is based on the assumption that long run queue are driven
by lots of CPU bound tasks that, with this architecture in place, will
find home inside the CPU bound tasks run queue. This means that I/O bound
tasks will have a better scheduler latency due to the fact the the run
queue load is moved inside the CPU bound tasks queue. This is important
because an high scheduler latency when weighed with a low task average
run time ( typical of I/O bound processes ) will result in an high percent
of performance loss. On the other side, the cost of traversing the CPU
bound tasks run queue will be weighed with a typical high average run time
resulting in a very little performance degradation. The task classification
should be done using the ->counter value, by saying that, for example,
tasks with counter > K belong to the I/O bound queue while
other ones belong to the CPU bound queue. By having K to be
the time slice that SCHED_OTHER ( with nice == 0 ) tasks usually get from
the scheduler, a good task classification can be achieved due to the fact
that I/O bound tasks are typically out of the run queue, receiving counter
accumulation from the recalculation loop. Even if by using a dual queue
( per CPU ) design would improve the scheduler latency, it's my oppinion
that the proposed Balanced Multi Queue Scheduler alone will be enough to
drive the latency down to more than acceptable values. This is proved by
the fact that the old scheduler did a good job with UP systems and, since
the multi queue design will load it in the same way, I've a big faith the
this implementation will be sufficent to drive pretty "nice" SMP systems.
The Balanced Multi Queue Scheduler, BMQS patch is available here
:
1) First Version Of The Balanced Multi Queue Scheduler
http://www.xmailserver.org/linux-patches/mss.html
2) Linux Kernel:
http://www.kernel.org/
3) My Linux Scheduler Stuff Page:
http://www.xmailserver.org/linux-patches/lnxsched.html
4) Linux Scheduler Scalability:
http://lse.sourceforge.net/scheduling
5) ACM Digital Libray
http://www.acm.org/
6) OSDLAB
http://www.osdlab.org/